
Markdownベースのブログシステム
Markdownファイルで記事を管理し、全文検索とタグフィルタリングを実装した、開発者のための本格的なブログシステムです。
実装プロジェクト
このブログシステムの実装例が実際に動作しているデモサイトを確認できます。
- デモサイト: https://shuji-bonji.github.io/svelte5-blog-markdown/
- ソースコード: https://github.com/shuji-bonji/svelte5-blog-markdown
- Viteのglob importによるMarkdownファイルの自動読み込み
- MiniSearchを使った全文検索の実装
- タグシステムとクライアントサイドフィルタリング
- Front-matterによるメタデータ管理
- 静的サイト生成での制約と対処法
スクリーンショット
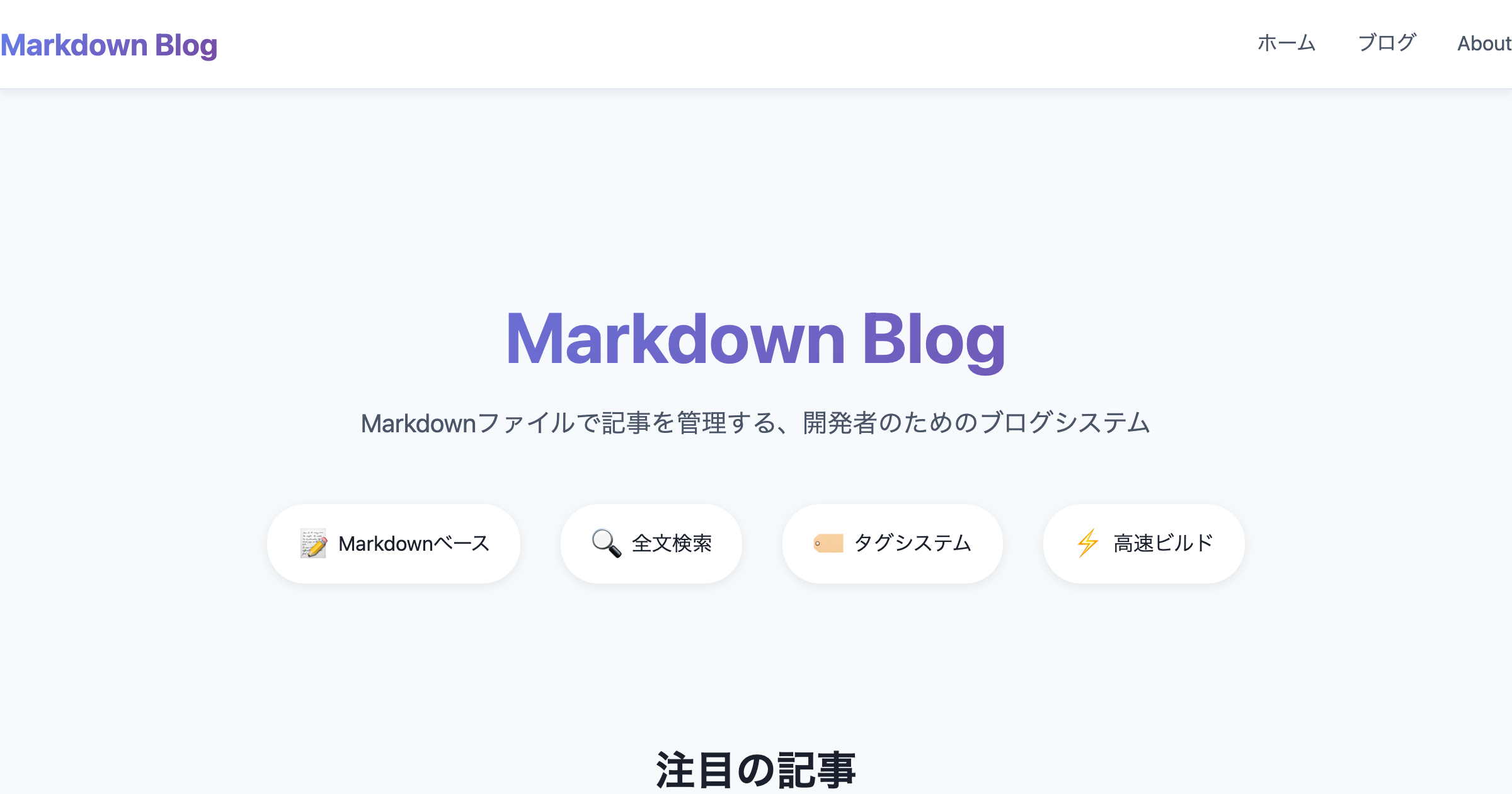
Markdown Blog
特徴
Markdownベースの記事管理
すべての記事はMarkdownファイルとして管理され、GitHubでバージョン管理できます。
---
title: 記事のタイトル
description: 記事の概要説明(検索対象にもなります)
date: 2025-01-08
author: 著者名
tags: [Svelte 5, TypeScript, Markdown]
published: true
featured: false
---
記事の本文...全文検索機能
MiniSearchライブラリを使用した高速な全文検索を実装。タイトル、説明、本文、タグすべてを対象に検索できます。
タグシステム
記事にタグを付けることで、カテゴリ別に記事を整理。タグクラウドとクライアントサイドでのフィルタリングが可能です。
プロジェクト構成
svelte5-blog-markdown/
├── content/
│ └── posts/ # Markdown記事
│ ├── 2025-01-08-markdown-powered-blog.md
│ ├── 2025-01-07-svelte5-features.md
│ └── 2025-01-06-typescript-tips.md
├── src/
│ ├── lib/
│ │ ├── components/ # UIコンポーネント
│ │ │ ├── ArticleCard.svelte
│ │ │ ├── SearchBox.svelte
│ │ │ └── TagCloud.svelte
│ │ ├── data/
│ │ │ └── articles.ts # 記事データ管理
│ │ ├── utils/
│ │ │ ├── markdown.ts # Markdown処理
│ │ │ └── search.ts # 検索エンジン
│ │ └── types/
│ │ └── blog.ts # TypeScript型定義
│ └── routes/
│ ├── +layout.svelte # 全体レイアウト
│ ├── +page.svelte # ホームページ
│ ├── about/
│ │ └── +page.svelte # Aboutページ
│ └── blog/
│ ├── +page.svelte # 記事一覧
│ └── [slug]/
│ ├── +page.svelte # 個別記事
│ └── +page.ts # 記事データ取得
└── static/
└── favicon.svg # ファビコン技術実装
Markdownファイルの自動読み込み
Viteのglob importを使用して、ビルド時にすべてのMarkdownファイルを自動的に読み込みます。
// src/lib/data/articles.ts
import type { Article } from '$lib/types/blog';
import {
parseMarkdown,
getSlugFromPath,
sortArticlesByDate,
} from '$lib/utils/markdown';
// すべてのMarkdownファイルをインポート
const markdownFiles = import.meta.glob('/content/posts/*.md', {
query: '?raw',
import: 'default',
eager: true,
});
// 記事をパースして配列に変換
const allArticles: Article[] = Object.entries(markdownFiles).map(
([path, content]) => {
const slug = getSlugFromPath(path);
return parseMarkdown(slug, content as string);
},
);
// 公開記事のみ取得し、日付順にソート
export const articles = sortArticlesByDate(
filterPublishedArticles(allArticles),
);Markdown処理とFront-matter
// src/lib/utils/markdown.ts
import { marked } from 'marked';
import fm from 'front-matter';
import type { Article, ArticleFrontmatter } from '$lib/types/blog';
// 簡易的な読了時間計算
function calculateReadingTime(text: string) {
const wordsPerMinute = 200;
const wordCount = text.trim().split(/s+/).length;
const minutes = Math.ceil(wordCount / wordsPerMinute);
return {
text: `${minutes}分で読めます`,
minutes,
time: minutes * 60 * 1000,
words: wordCount,
};
}
/**
* 本文先頭の「# タイトル」行が frontmatter の title と一致する場合に除去する。
* これにより、ページ側の <h1> と本文冒頭の h1 の二重表示を防ぐ。
* Markdown 執筆者は # を書いても書かなくても同じ結果になる。
*/
function stripLeadingH1(body: string, title: string): string {
const lines = body.split('
');
// 先頭の空行をスキップ
let i = 0;
while (i < lines.length && lines[i].trim() === '') i++;
const firstLine = lines[i];
if (!firstLine) return body;
// ATX 形式の h1 (# ...) にマッチ。h2 以降 (##) は除外。
const match = firstLine.match(/^#s+(.+?)s*#*s*$/);
if (!match) return body;
if (match[1].trim() === title.trim()) {
// # タイトル行とその直後の空行を除去
return lines
.slice(i + 1)
.join('
')
.replace(/^
+/, '');
}
return body;
}
export function parseMarkdown(slug: string, markdown: string): Article {
const { attributes, body } = fm<ArticleFrontmatter>(markdown);
// frontmatter に title がある場合、本文冒頭の重複 h1 を除去する
const normalizedBody = stripLeadingH1(body, attributes.title);
// marked v16: async オプションを明示して string を返すオーバーロードを選択する
const html = marked.parse(normalizedBody, { async: false });
const stats = calculateReadingTime(normalizedBody);
return {
slug,
frontmatter: attributes,
content: body,
html,
readingTime: stats,
};
}Markdown 記事の先頭に慣習で # タイトル を書く執筆者は多いですが、frontmatter にも title があり、ページ側で <h1> としてレンダリングすると 同じタイトルが二回表示されてしまいます。 stripLeadingH1 は「本文の最初の非空行が # タイトル かつ frontmatter の title と一致する場合のみ除去」します。h2 以降や別テキストの # は残すので、Markdown 側に書いても書かなくても同じ結果になり、執筆者体験が安定します。
全文検索の実装
MiniSearchを使用した高速な全文検索エンジンの実装です。
// src/lib/utils/search.ts
import MiniSearch from 'minisearch';
import type { Article, SearchableArticle } from '$lib/types/blog';
export function createSearchIndex(articles: Article[]) {
const searchableArticles: SearchableArticle[] = articles.map((article) => ({
...article,
id: article.slug,
searchableText: `${article.frontmatter.title} ${article.frontmatter.description} ${article.content}`,
}));
const miniSearch = new MiniSearch<SearchableArticle>({
fields: [
'frontmatter.title',
'frontmatter.description',
'searchableText',
'frontmatter.tags',
],
storeFields: ['slug', 'frontmatter'],
searchOptions: {
boost: {
'frontmatter.title': 3,
'frontmatter.tags': 2,
'frontmatter.description': 1.5,
},
fuzzy: 0.2,
prefix: true,
},
});
miniSearch.addAll(searchableArticles);
return miniSearch;
}検索コンポーネント
<!-- src/lib/components/SearchBox.svelte -->
<script lang="ts">
let {
onSearch,
placeholder = '記事を検索...'
}: {
onSearch: (query: string) => void;
placeholder?: string;
} = $props();
let query = $state('');
let debounceTimer: ReturnType<typeof setTimeout>;
function handleInput() {
clearTimeout(debounceTimer);
debounceTimer = setTimeout(() => {
onSearch(query);
}, 300);
}
</script>
<div class="search-box">
<input
type="search"
bind:value={query}
oninput={handleInput}
{placeholder}
class="search-input"
/>
</div>タグクラウドコンポーネント
<!-- src/lib/components/TagCloud.svelte -->
<script lang="ts">
let {
tags,
selectedTag = null,
onTagSelect
}: {
tags: Map<string, number>;
selectedTag?: string | null;
onTagSelect?: (tag: string | null) => void;
} = $props();
// タグのサイズを計算(記事数に応じて)
function getTagSize(count: number): string {
const maxCount = Math.max(...tags.values());
const ratio = count / maxCount;
if (ratio > 0.8) return 'xl';
if (ratio > 0.6) return 'lg';
if (ratio > 0.4) return 'md';
if (ratio > 0.2) return 'sm';
return 'xs';
}
</script>
<div class="tag-cloud">
<h3>タグ</h3>
<div class="tags">
<button
onclick={() => onTagSelect?.(null)}
class="tag tag-all"
class:selected={!selectedTag}
>
すべて
</button>
{#each [...tags.entries()] as [tag, count] (tag)}
<button
onclick={() => onTagSelect?.(tag)}
class="tag tag-{getTagSize(count)}"
class:selected={selectedTag === tag}
title="{count}件の記事"
>
{tag}
<span class="count">{count}</span>
</button>
{/each}
</div>
</div>ブログ一覧ページ
検索とタグフィルタリングを統合したブログ一覧ページです。
<!-- src/routes/blog/+page.svelte -->
<script lang="ts">
import { articles, getAllTags } from '$lib/data/articles';
import { createSearchIndex, searchArticles } from '$lib/utils/search';
import { getArticlesByTag } from '$lib/utils/markdown';
import ArticleCard from '$lib/components/ArticleCard.svelte';
import SearchBox from '$lib/components/SearchBox.svelte';
import TagCloud from '$lib/components/TagCloud.svelte';
// 検索インデックスを作成
const searchIndex = createSearchIndex(articles);
const allTags = getAllTags();
let searchQuery = $state('');
let searchResults = $state<typeof articles>([]);
let isSearching = $state(false);
let selectedTag = $state<string | null>(null);
// 表示する記事を決定
let displayArticles = $derived(
isSearching && searchQuery
? searchResults
: selectedTag
? getArticlesByTag(articles, selectedTag)
: articles
);
function handleSearch(query: string) {
searchQuery = query;
if (query) {
isSearching = true;
searchResults = searchArticles(searchIndex, query);
} else {
isSearching = false;
searchResults = [];
}
}
</script>
<div class="container">
<div class="search-section">
<SearchBox onSearch={handleSearch} />
</div>
<div class="content-layout">
<aside class="sidebar">
<TagCloud
tags={allTags}
{selectedTag}
onTagSelect={(tag) => selectedTag = tag}
/>
</aside>
<div class="articles-section">
{#if isSearching && searchQuery}
<div class="search-info">
「{searchQuery}」の検索結果: {searchResults.length}件
</div>
{/if}
{#if selectedTag}
<div class="tag-info">
タグ「{selectedTag}」の記事: {displayArticles.length}件
<button onclick={() => selectedTag = null} class="clear-filter">
× フィルターをクリア
</button>
</div>
{/if}
<div class="articles-grid">
{#each displayArticles as article (article.id)}
<ArticleCard {article} />
{/each}
</div>
</div>
</div>
</div>静的サイト生成での注意点
SvelteKitで静的サイト生成(SSG)を行う場合、url.searchParamsはビルド時に使用できません。
そのため、タグフィルタリングなどの動的な機能は、クライアントサイドで実装する必要があります。
// ❌ 静的生成では使えない($app/state の page も SSG では URL パラメータを評価できない)
import { page } from '$app/state';
let selectedTag = $derived(page.url.searchParams.get('tag'));
// ✅ クライアントサイドで管理
let selectedTag = $state<string | null>(null);パフォーマンス最適化
1. ビルド時の記事読み込み
すべての記事はビルド時に読み込まれ、バンドルに含まれます。これにより、ランタイムでのファイル読み込みが不要になります。
2. 検索インデックスの事前構築
検索インデックスはページロード時に一度だけ構築され、メモリに保持されます。
3. デバウンス処理
検索入力にはデバウンス処理を適用し、不要な検索実行を防いでいます。
まとめ
このMarkdownベースのブログシステムは、開発者にとって理想的な記事管理方法を提供します。
主な利点
- GitHubでバージョン管理可能
- VSCodeで快適に執筆
- 高速な全文検索
- 柔軟なタグシステム
- 静的サイト生成による高速配信
学んだ技術
- Viteのglob import
- Front-matterパース
- MiniSearch統合
- クライアントサイド検索
- Svelte 5 Runesシステム
関連リンク
- ブログシステム実装例(基礎編) - 静的データを使った最小構成
- Markdownガイド - Markdown記法リファレンス
- MiniSearch - 全文検索ライブラリ